

Introduction
OpenAI: NOOOOO, that Chinese company Deepseek stole the data we've stolen to train their model... This is against our platform policy, they should be ashamed.
We changed our mind about stealing data, we think it's bad now.
What is Deepseek ?
Deepseek is a Chinese AI company founded by Liang Wenfeng in mid-2023 and based in Hangzhou, Zhejiang. They built their model at a fraction of the cost normally expected. Their R1 model claims to outperform OpenAI's o1 model.
The launch of Deepseek R1 affected technology stocks tied to AI, including Microsoft, Nvidia Corp, Oracle Corp, and Alphabet Inc on Monday, wiping almost $1 trillion in market value.
Deepseek is open source under MIT license(aka free-for-all use), and very sweet for commercial purposes. 😋
Understanding Model Distillation
Model distillation is a process where a small model learns to mimic a larger one. In AI, this means a compact model can capture much of the intelligence of a larger model without needing the same level of computing power. Distillation works by feeding the large model a bunch of questions and capturing its responses to become the training data for another model.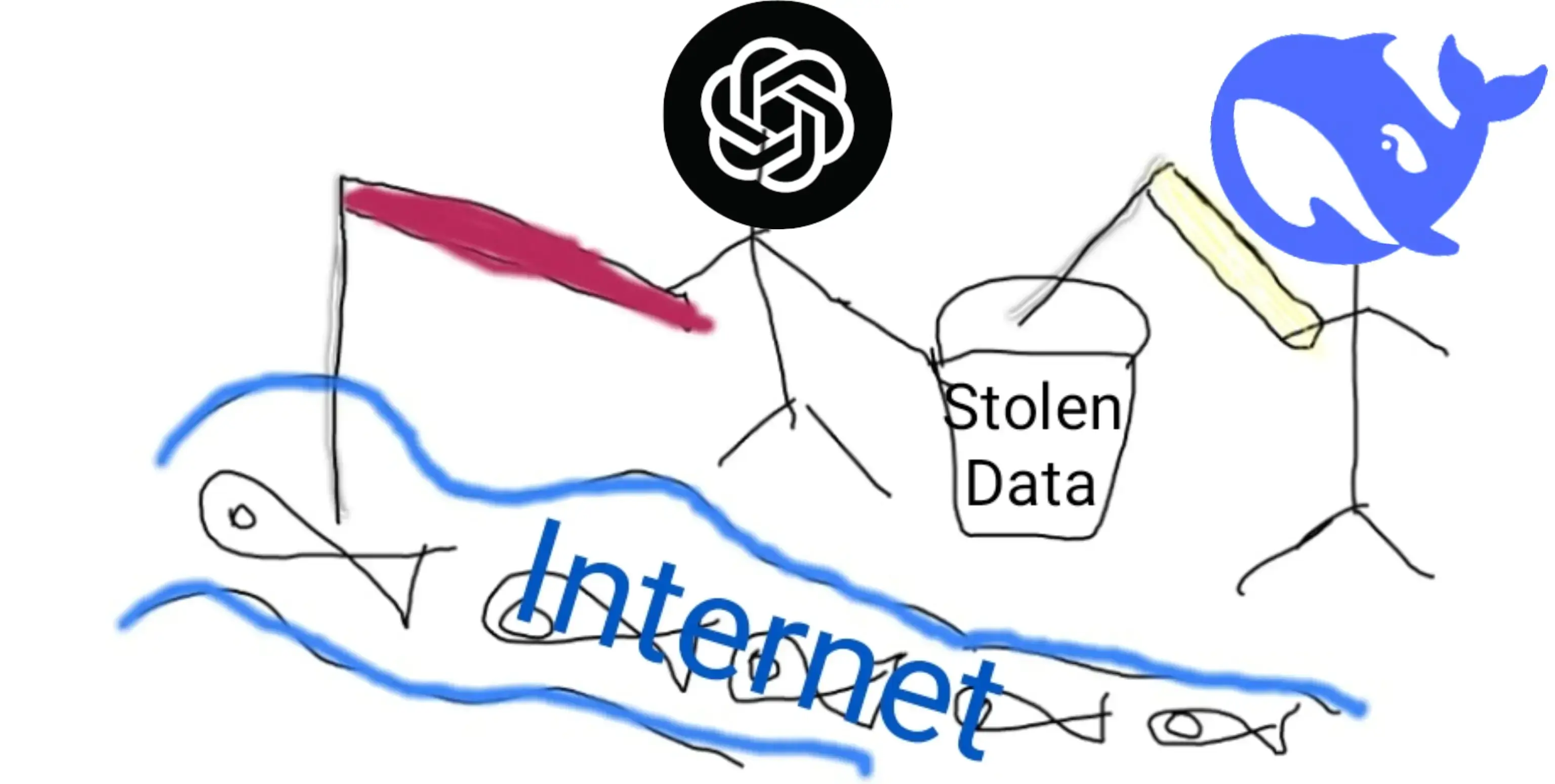 Save This is actually a common practice for AI startups.
Save This is actually a common practice for AI startups.
{kind=link}
How OpenAI get training data to train GPT models
GPT models are trained from a high amount of text stolen from countless online sources such as websites, e-books, news articles, etc. This allows the models to have human-like responses and ensure comprehensive coverage of topics.
Deepseek's training method
Recent reports suggest that instead of gathering raw training data from scratch, Deepseek may be using ChatGPT's responses to train its model.
While OpenAI steals data from the Internet, Deepseek is reported to be making API requests to OpenAI's API to capture ChatGPT's output. The outputs then serve as part of the training data for Deepseek's model.
This strategy is known as knowledge distillation, allowing Deepseek to train its model at a much lower cost.
OpenAI API is an application programming interface that allows users to pay for getting model responses using OpenAI's servers instead of hosting the model locally.
Evidence of Deepseek's Tactics
Researchers from Microsoft have noticed that a group associated with Deepseek has been sending a very high volume of requests to OpenAI's API. These requests are far more frequent than what would be expected for routine usage. Such abnormal behaviour suggests that the group is harvesting a large number of responses from ChatGPT.
OpenAI's response
OpenAI is now in full panic mode.
OpenAI has confirmed that Deepseek may have "inappropriately distilled" its models. The company stresses that it takes aggressive countermeasures to protect its technology.
Cost Comparison: Deepseek vs OpenAI
Two Teams:
- Deepseek claims that their R1 model was trained for around $5.6 million.
- While OpenAI spent roughly $100 million in computing costs, using the world's best GPUs.
The model distillation method allows Deepseek to cut training costs by as much as 95% compared to what companies like OpenAI spend.
Moreover, the Deepseek R1 model itself costs a significantly low amount of computing power and doesn't require powerful Nvidia GPUs. If you don't believe this, download Ollama on an old potato computer and run it to see how smooth and performant it is!
Best part: Deepseek is open source! Anyone can run it locally without an Internet connection, providing the best privacy.
A quote from a Reddit user:
Unlike OpenAI, Deepseek is actually Open AI.
My Opinion
OpenAI has a policy that says that users shouldn't "copy" any of its services or use outputs to train another model competing with OpenAI.
However, I believe most websites also have terms stating and don't like anyone, including web scrapers that are not from search engines, to scrape their content and use it for generating profits. OpenAI is stealing everyone's hard work.
And now OpenAI is going to feel the pain that those publishers might have, "NOOOOO, that Chinese company stole the data I've stolen to train their model!" It’s like a thief calling the police because someone stole the ice cream they had stolen first.
If you're affected, you can't just blame OpenAI; most giant tech companies do the same way. For instance, "AI Overviews" are decreasing the CTRs(Click Through Rates) of websites and allowing Google to show more ads in SERPs.
OpenAI is actually the most beneficial when compared with the publishers; Deepseek pays to scrape data from OpenAI's API. On the other hand, OpenAI pays nothing to publishers when the publishers lose money to handle traffic from OpenAI.
Conclusion
We can see how the US overreacted lol, and it's sad that the government actually stands on the OpenAI side.
Deepseek is a wake-up call for us whether a successful AI model really needs 6969 quintillion dollars to make, while the competitive landscape is changing, with cost‑efficient methods challenging traditional, resource‑intensive approaches.
Read More: DeepSeek Introduces NSA - Ultra-Fast Long-Context Model Training and Inference