

Introduction
DeepSeek just introduced an ultra-fast long-context model training and inference system. This breakthrough, known as NSA (Native Sparse Attention), changes the way AI models handle long texts and speed up long context language model training in a cheaper, efficient way while maintaining accuracy.
NSA outperforms full attention: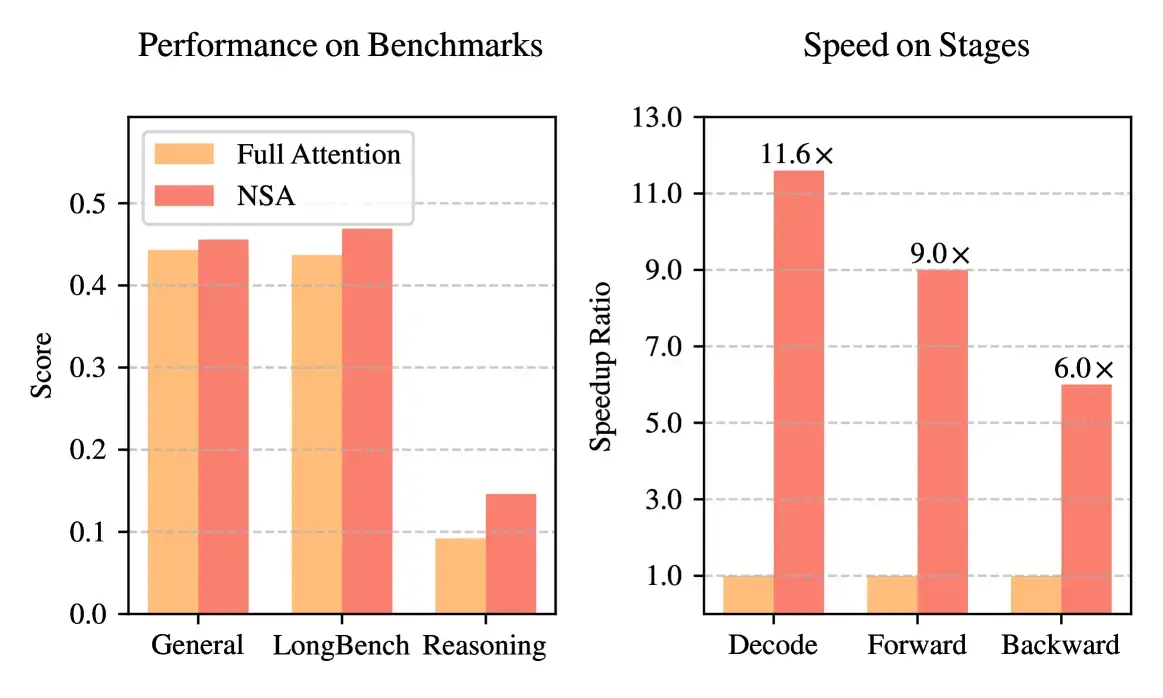 Save
Save
The images in this article came from arxiv.org
The Problem with Traditional Method
What traditional language models use is known as full attention. In full attention, every token in a text interacts with every other token. This ensures nothing is missed, but it will be costly when the number of tokens increases. The number of interactions will increase with the square of the number of tokens so there will be 100 million interactions for a text with 10,000 tokens.
When a chatbot is needed to process lengthy legal documents or hold extended conversations, full attention can cause high delays and costs.
This is inefficient and increases computing power very quickly.
How NSA Works
Rather than forcing every token to interact with every other, NSA focuses on only the most important parts of the text. It works by reducing the number of tokens without losing the main ideas.
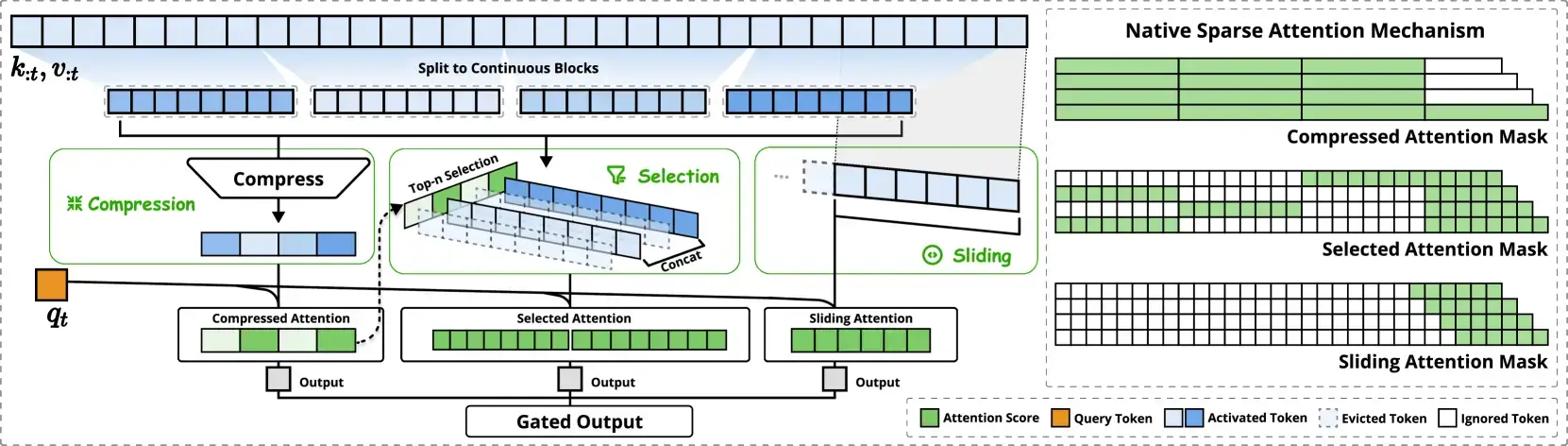
NSA uses a hierarchical strategy that organises the text into layers. At the highest level, NSA captures the overall structure and then zooms in to pick out the details.
3 main parts:
- Compression: The model groups nearby words into blocks, much like summarising each paragraph into a headline. A small neural network then converts each block into a single token that captures the main idea.
- Selection: Once compressed into tokens, NSA decide which tokens are worth paying attention to. It assigns an “importance score” to each block by using intermediate information from the compression step.
- Sliding Window: Even if it had a great summary of the whole document, it still needs to pay attention to the most recent or nearby words to get a full understanding. This mechanism ensures the immediate contexts aren't lost. It takes a fixed number of the latest tokens and processes them separately to capture local nuances.
Speed and Efficiency
You may get deeper details by reading the research paper.
NSA is optimized for today’s GPUs, especially Nvidia’s H800 series.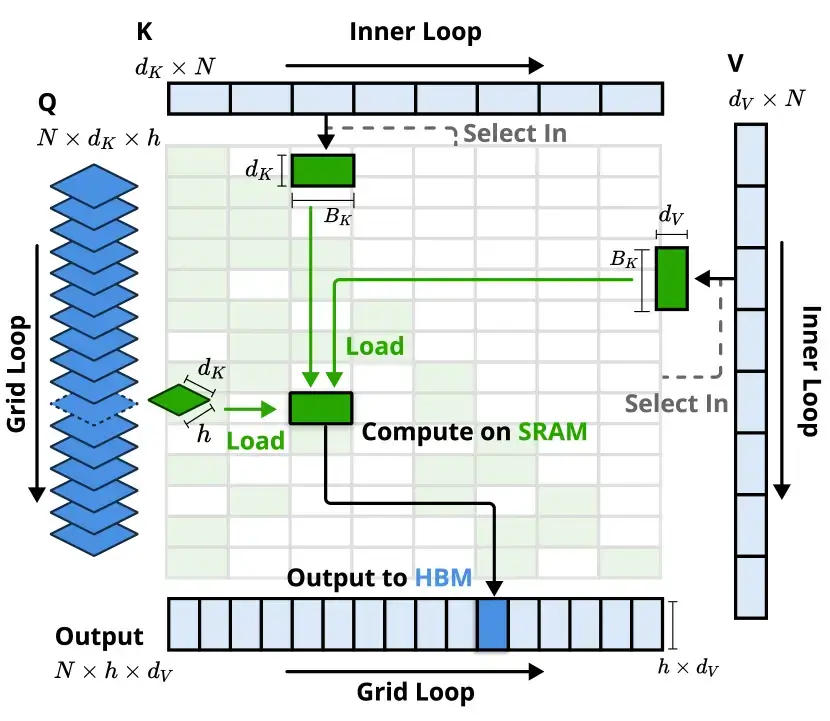 Save Using custom code built with the Triton framework, NSA’s design loads groups of tokens into very fast memory (SRAM) and processes them in parallel. By reducing repeated memory access, NSA cuts down on wasted time and speeds up the performance.
Save Using custom code built with the Triton framework, NSA’s design loads groups of tokens into very fast memory (SRAM) and processes them in parallel. By reducing repeated memory access, NSA cuts down on wasted time and speeds up the performance.
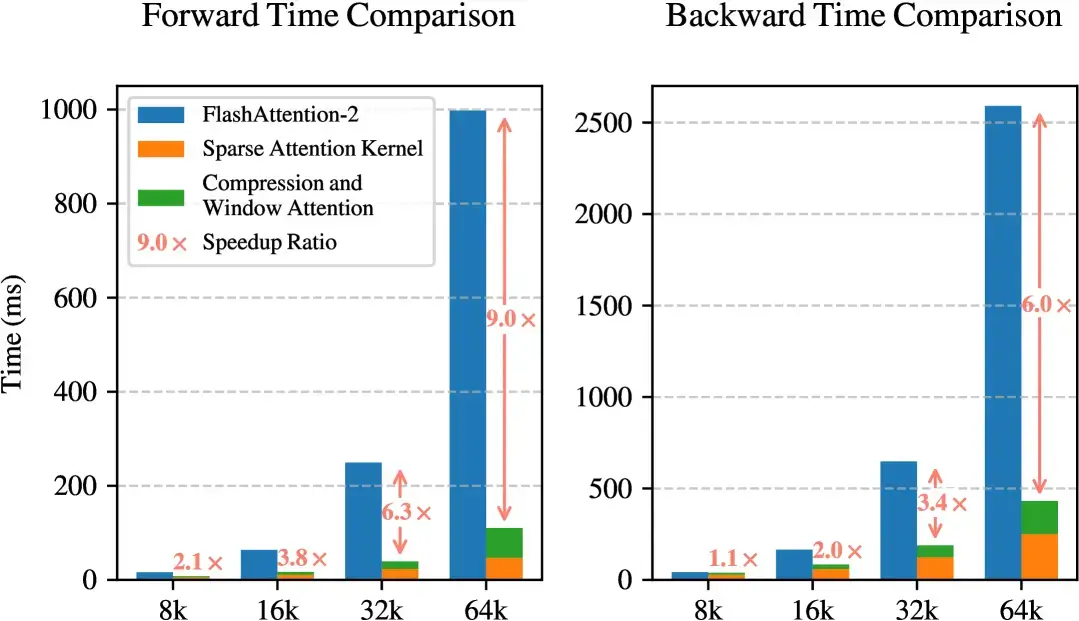
For instance, in tests on an 8-GPU system, NSA’s optimised kernels delivered up to nine times faster forward passes and six times faster backward passes when processing sequences of 64,000 tokens. During decoding (when the model generates text), NSA only needs to load a small fraction of tokens instead of the full set. This results in speedups of more than 11 times compared to traditional methods.
Real-World Testing
In a test, NSA was evaluated on a transformer model with 27 billion parameters, though only 3 billion of those were active at any one time. This model was spread across 30 layers and used a method called Mixture-of-Experts (which divides the workload among several specialised parts) to handle the data.
The training was carried out on a dataset of 270 billion tokens. Initially, the model worked with 8,000 tokens and then fine-tuned on texts stretching up to 32,000 tokens.
When tested on various benchmarks such as knowledge tests (like MMLU), math problem sets (like GSM8K), reading comprehension tests (like DROP), and even coding challenges (MBPP and HumanEval), NSA consistently matched or outperformed the full attention approach.
One particularly impressive test was the “needle-in-a-haystack” challenge, where the NSA had to retrieve a small piece of information from a 64,000-token document. NSA achieved perfect accuracy, which proves its capability to handle very long contexts with ease. Furthermore, when fine-tuned for step-by-step reasoning (known as chain-of-thought), the NSA version of the model scored significantly higher on a difficult math exam (AIME 24) than the full attention model.
NSA also processes faster than full attention:
| Metric | NSA | Full Attention |
|---|---|---|
| Tokens processed/second | 4,900 | 420 |
| Response time (10k tokens) | 2.1 sec | 23.8 sec |
Efficiency Gains and Impact
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- 9x faster training (forward passes)
- 6x faster learning (backward passes)
- 11.6 faster text generation (decoding)
- able to handle 3x more conversations
Impact: A 64k token sequence that once took 10 hours with full attention now finishes in under 55 minutes and saving $2,200 per day!
NSA is much more cheaper, faster, and higher efficiency than full attention!
NSA Versus Other Methods
| Native Sparse Attention | Full Attention | |
|---|---|---|
| Computational | Uses a hierarchical approach that cuts down interactions | Every token interacts with every other token |
| Inference Speedup | Up to 11.6× faster decoding; 9× forward, 6× backward speed at 64k tokens | Baseline speed; no inherent speedup |
| Memory Access Efficiency | Loads only selected token blocks; group-wise and block-based, reducing redundant memory transfers | Must access the full key-value cache for each query |
| Efficiency | Optimised custom Triton kernels on modern GPUs (e.g., Nvidia H800) provide high throughput | Standard implementation; slower with long sequences |
| Costs | Lower computational and energy costs; reduced need for expensive hardware | High hardware and energy costs; more expensive to scale |
| Performance on Benchmarks | Matches or outperforms full attention on long-context tasks and reasoning challenges | Strong accuracy but suffers on long-context and reasoning tasks |
Conclusion
AI developments are getting better and better. NSA is trying to make language modelling more accessible. In the future, everyone can train a powerful advanced model at a low cost and reduce carbon footprints, not just for giant tech companies with deep pockets.
Read More: How DeepSeek Copy ChatGPT